浏览器缓存机制
作者:Seiya
时间:2019年09月02日
前言
在前端开发中,性能一直都是被大家所重视的一点,然而判断一个网站的性能最直观的就是看网页打开的速度。其中提高网页反应速度的一个方式就是使用缓存。
一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,并且由于缓存文件可以重复利用,还可以减少带宽,降低网络负荷。
缓存位置
从缓存位置上来说分为四种,并且各自有优先级,当依次查找缓存且都没有命中的时候,才会去请求网络:
Service Worker
Memory Cache
Disk Cache
Push Cache
网络请求
Service Worker
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。使用 Service Worker的话,传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。
Service Worker 实现缓存功能一般分为三个步骤:首先需要先注册 Service Worker,然后监听到 install 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。以下是这个步骤的实现:
// index.js
if (navigator.serviceWorker) {
navigator.serviceWorker
.register('sw.js')
.then(function(registration) {
console.log('service worker 注册成功')
})
.catch(function(err) {
console.log('servcie worker 注册失败')
})
}
// sw.js
// 监听 `install` 事件,回调中缓存所需文件
self.addEventListener('install', e => {
e.waitUntil(
caches.open('my-cache').then(function(cache) {
return cache.addAll(['./index.html', './index.js'])
})
)
})
// 拦截所有请求事件
// 如果缓存中已经有请求的数据就直接用缓存,否则去请求数据
self.addEventListener('fetch', e => {
e.respondWith(
caches.match(e.request).then(function(response) {
if (response) {
return response
}
console.log('fetch source')
})
)
})
<div class="md-section-divider"></div>
Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
当 Service Worker 没有命中缓存的时候,我们需要去调用 fetch 函数获取数据。也就是说,如果我们没有在 Service Worker 命中缓存的话,会根据缓存查找优先级去查找数据。
但是不管我们是从 Memory Cache 中还是从网络请求中获取的数据,浏览器都会显示我们是从 Service Worker 中获取的内容。
Memory Cache
Memory Cache 也就是内存中的缓存,读取内存中的数据肯定比磁盘快。但是内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。 一旦我们关闭 Tab 页面,内存中的缓存也就被释放了。当我们访问过页面以后,再次刷新页面,可以发现很多数据都来自于内存缓存。
对于大文件来说,大概率是不存储在内存中的,反之优先
当前系统内存使用率高的话,文件优先存储进硬盘
Disk Cache
Disk Cache 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上。
在所有浏览器缓存中,Disk Cache 覆盖面基本是最大的。它会根据 HTTP Herder 中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据。
Push Cache
Push Cache 是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。并且缓存时间也很短暂,只在会话(Session)中存在,一旦会话结束就被释放。
所有的资源都能被推送,但是 Edge 和 Safari 浏览器兼容性不怎么好;
可以推送 no-cache 和 no-store 的资源;
一旦连接被关闭,Push Cache 就被释放;
多个页面可以使用相同的 HTTP/2 连接,也就是说能使用同样的缓存;
Push Cache 中的缓存只能被使用一次;
浏览器可以拒绝接受已经存在的资源推送;
你可以给其他域名推送资源;
网络请求
如果所有缓存都没有命中的话,那么只能发起请求来获取资源了。为了性能上的考虑,大部分的接口都应该选择好缓存策略。
缓存策略
浏览器对于请求资源, 拥有一系列成熟的缓存策略。按照发生的时间顺序分别为存储策略, 过期策略, 协商策略, 其中存储策略在收到响应后应用, 过期策略, 协商策略在发送请求前应用。流程图如下所示:
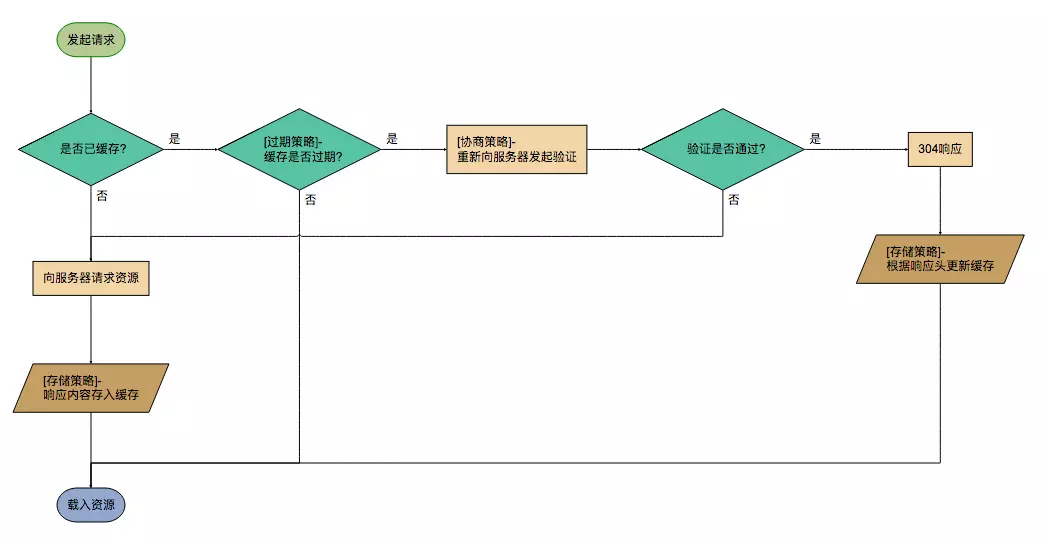
强缓存
强缓存可以通过设置两种 HTTP Header 实现:Expires 和 Cache-Control 。强缓存表示在缓存期间不需要请求,state code 为 200。
ExpiresExpires 是 HTTP/1 的产物,表示资源会在指定时间后过期,需要再次请求。并且 Expires 受限于本地时间,如果修改了本地时间,可能会造成缓存失效。
Cache-controlCache-control: max-age=30Cache-Control 出现于 HTTP/1.1,优先级高于 Expires 。该属性值表示资源会在 30 秒后过期,需要再次请求。
Cache-Control 可以在请求头或者响应头中设置,并且可以组合使用多种指令
协商缓存
如果缓存过期了,就需要发起请求验证资源是否有更新。协商缓存可以通过设置两种 HTTP Header 实现:Last-Modified 和 ETag 。
当浏览器发起请求验证资源时,如果资源没有做改变,那么服务端就会返回 304 状态码,并且更新浏览器缓存有效期。
Last-Modified和If-Modified-SinceLast-Modified 表示本地文件最后修改日期,If-Modified-Since 会将 Last-Modified 的值发送给服务器,询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来,否则返回 304 状态码。
但是 Last-Modified 存在一些弊端:如果本地打开缓存文件,即使没有对文件进行修改,但还是会造成 Last-Modified 被修改,服务端不能命中缓存导致发送相同的资源;
因为 `Last-Modified 只能以秒计时,如果在不可感知的时间内修改完成文件,那么服务端会认为资源还是命中了,不会返回正确的资源;
ETag和If-None-MatchETag 类似于文件指纹,If-None-Match 会将当前 ETag 发送给服务器,询问该资源 ETag 是否变动,有变动的话就将新的资源发送回来。并且ETag 优先级比 Last-Modified 高。
如果什么缓存策略都没设置,那么浏览器会怎么处理?
浏览器会采用一个启发式的算法,通常会取响应头中的 Date 减去 Last-Modified 值的 10% 作为缓存时间。
实际场景下的缓存策略
频繁变动的资源
对于频繁变动的资源,首先需要使用 Cache-Control: no-cache 使浏览器每次都请求服务器,然后配合 ETag 或者 Last-Modified 来验证资源是否有效。这样的做法虽然不能节省请求数量,但是能显著减少响应数据大小。
代码文件
这里特指除了 HTML 外的代码文件,因为 HTML 文件一般不缓存或者缓存时间很短。
一般来说,现在都会使用工具来打包代码,那么我们就可以对文件名进行哈希处理,只有当代码修改后才会生成新的文件名。基于此,我们就可以给代码文件设置缓存有效期一年 Cache-Control: max-age=31536000,这样只有当 HTML 文件中引入的文件名发生了改变才会去下载最新的代码文件,否则就一直使用缓存。