输入 URL 到页面渲染的整个流程
作者:Seiya
时间:2019年09月01日
DNS 查询
DNS 的作用就是通过域名查询到具体的 IP。因为 IP 存在数字和英文的组合(IPv6),很不利于人类记忆,所以就出现了域名。我们可以把域名看成是某个 IP 的别名,DNS 就是去查询这个别名的真正名称是什么。
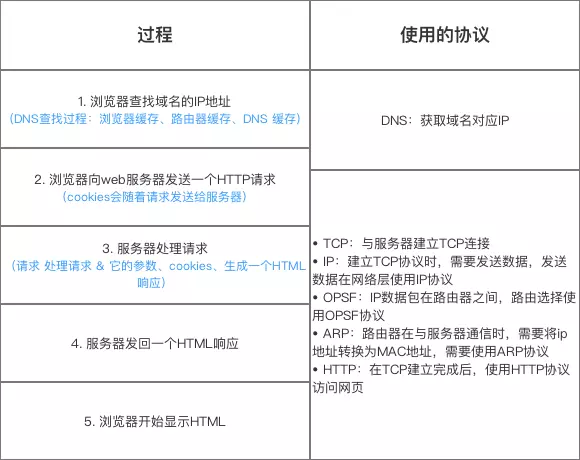
在 TCP 握手之前就已经进行了 DNS 查询,这个查询是操作系统自己做的。当你在浏览器中想访问 www.google.com 时,会进行一下操作:
浏览器检查域名是否在缓存当中(要查看 Chrome 当中的缓存, 打开 chrome://net-internals/#dns);
如果缓存中没有,就去调用系统库函数,操作系统会在本地 Hosts 缓存中查询 IP;
如果找不到的话,将会向 DNS 服务器发送一条 DNS 查询请求。DNS 服务器是由网络通信栈提供的,通常是本地路由器或者 ISP 的缓存 DNS 服务器;
查询本地 DNS 服务器;
如果这时候还没得话,会直接去 DNS 根服务器查询,这一步查询会找出负责 com 这个一级域名的服务器;
然后去该服务器查询 google 这个二级域名;
接下来三级域名的查询其实是我们自己配置的,你可以给 www 这个域名配置一个 IP,然后还可以给别的三级域名配置一个 IP;
tips
以上介绍的是 DNS 迭代查询,还有种是递归查询,区别就是前者是由客户端去做请求,后者是由系统配置的 DNS 服务器做请求,得到结果后将数据返回给客户端。
建立连接,发送 HTTP 请求
封装报文
当浏览器得到了目标服务器的 IP 地址,以及 URL 中给出来端口号(http 协议默认端口号是 80, https 默认端口号是 443),它会调用系统库函数 socket ,请求一个 TCP流套接字。
这个请求首先被交给传输层,在传输层请求被封装成 TCP segment。目标端口会被加入头部,源端口会在系统内核的动态端口范围内选取;
TCP segment 被送往网络层,网络层会在其中再加入一个 IP 头部,里面包含了目标服务器的IP地址以及本机的IP地址,把它封装成一个IP packet;
这个 TCP packet 接下来会进入链路层,链路层会在封包中加入 frame 头部,里面包含了本地内置网卡的MAC地址以及网关(本地路由器)的 MAC 地址。如果内核不知道网关的 MAC 地址,它必须进行 ARP 广播来查询其地址。
发送数据
至此,TCP 封包已经准备好了,可以使用下面的方式进行传输,并最终到达目标服务器:
以太网;
WiFi;
蜂窝数据网络;
建立连接
第一步:TCP 握手
第一次握手:客户端选择一个初始序列号(ISN),将设置了 SYN 位的封包发送给服务器端,表明自己要建立连接并设置了初始序列号;第二次握手:服务器端接收到 SYN 包,如果它可以建立连接:服务器端选择它自己的初始序列号;
服务器端设置 SYN 位,表明自己选择了一个初始序列号;
服务器端把 (客户端ISN + 1) 复制到 ACK 域,并且设置 ACK 位,表明自己接收到了客户端的第一个封包;
第三次握手:客户端通过发送下面一个封包来确认这次连接:自己的序列号+1;
接收端 ACK+1;
设置 ACK 位;
关闭连接时:
要关闭连接的一方发送一个 FIN 包;
另一方确认这个 FIN 包,并且发送自己的 FIN 包;
要关闭的一方使用 ACK 包来确认接收到了 FIN;
第二步:TLS 握手
客户端发送一个
ClientHello消息到服务器端,消息中同时包含了它的 Transport Layer Security (TLS) 版本,可用的加密算法和压缩算法。服务器端向客户端返回一个
ServerHello消息,消息中包含了服务器端的 TLS 版本,服务器所选择的加密和压缩算法,以及数字证书认证机构(Certificate Authority,缩写 CA)签发的服务器公开证书,证书中包含了公钥。客户端会使用这个公钥加密接下来的握手过程,直到协商生成一个新的对称密钥;客户端根据自己的信任 CA 列表,验证服务器端的证书是否可信。如果认为可信,客户端会生成一串伪随机数,使用服务器的公钥加密它。这串随机数会被用于生成新的对称密钥;
服务器端使用自己的私钥解密上面提到的随机数,然后使用这串随机数生成自己的对称主密钥;
客户端发送一个
Finished消息给服务器端,使用对称密钥加密这次通讯的一个散列值;服务器端生成自己的 hash 值,然后解密客户端发送来的信息,检查这两个值是否对应。如果对应,就向客户端发送一个
Finished消息,也使用协商好的对称密钥加密;从现在开始,接下来整个 TLS 会话都使用对称秘钥进行加密,传输应用层(HTTP)内容;
服务端处理请求
HTTPD(HTTP Daemon)在服务器端处理请求/响应。最常见的 HTTPD 有 Linux 上常用的 Apache 和 nginx,以及 Windows 上的 IIS。
数据在进入服务端之前,可能还会先经过负责负载均衡的服务器,它的作用就是将请求合理的分发到多台服务器上。
HTTPD 接收请求
服务器把请求拆分为以下几个参数:
HTTP 请求方法(GET, POST, HEAD, PUT, DELETE, CONNECT, OPTIONS, 或者 TRACE)。直接在地址栏中输入 URL 这种情况下,使用的是 GET 方法;
域名:google.com;
请求路径/页面:/ (我们没有请求google.com下的指定的页面,因此 / 是默认的路径);
服务器验证其上已经配置了 google.com 的虚拟主机;
服务器验证 google.com 接受 GET 方法;
服务器验证该用户可以使用 GET 方法(根据 IP 地址,身份信息等);
如果服务器安装了 URL 重写模块(例如 Apache 的 mod_rewrite 和 IIS 的 URL Rewrite),服务器会尝试匹配重写规则,如果匹配上的话,服务器会按照规则重写这个请求;
服务端响应请求
服务器根据请求信息获取相应的响应内容,这种情况下由于访问路径是 "/" ,会访问首页文件(你可以重写这个规则,但是这个是最常用的)。
服务器会使用指定的处理程序分析处理这个文件,假如 Google 使用 PHP,服务器会使用 PHP 解析 index 文件,并捕获输出,把 PHP 的输出结果返回给请求者;
浏览器渲染页面
浏览器会判断状态码是什么,如果是 200 那就继续解析,如果 400 或 500 的话就会报错,如果 300 的话会进行重定向,这里会有个重定向计数器,避免过多次的重定向,超过次数也会报错;
浏览器开始解析文件,如果是 gzip 格式的话会先解压一下,然后通过文件的编码格式知道该如何去解码文件;
文件解码成功后会正式开始渲染流程,先会根据 HTML 构建 DOM 树,有 CSS 的话会去构建 CSSOM 树。如果遇到 script 标签的话,会判断是否存在 async 或者 defer ,前者会并行进行下载并执行 JS,后者会先下载文件,然后等待 HTML 解析完成后顺序执行;
如果以上都没有,就会阻塞住渲染流程直到 JS 执行完毕。遇到文件下载的会去下载文件,这里如果使用 HTTP/2 协议的话会极大的提高多图的下载效率。
CSSOM 树和 DOM 树构建完成后会开始生成 Render 树,这一步就是确定页面元素的布局、样式等等诸多方面的东西;
在生成 Render 树的过程中,浏览器就开始调用 GPU 绘制,合成图层,将内容显示在屏幕上;