Vue 全家桶
作者:Seiya
时间:2019年09月07日
Vuex
Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。
每一个 Vuex 应用的核心就是 store(仓库)。“store” 基本上就是一个容器,它包含着你的应用中大部分的状态 ( state )。主要包括以下几个模块:
State:定义了应用状态的数据结构,可以在这里设置默认的初始状态。Getter:允许组件从 Store 中获取数据,mapGetters 辅助函数仅仅是将 store 中的 getter 映射到局部计算属性。Mutation:是唯一更改 store 中状态的方法,且必须是同步函数。Action:用于提交 mutation,而不是直接变更状态,可以包含任意异步操作。Module:允许将单一的 Store 拆分为多个 store 且同时保存在单一的状态树中。
Vuex 的特点
Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样使得我们可以方便地跟踪每一个状态的变化。
为什么使用 Vuex
单向数据流
由于 Vue 是单向数据流。数据 state 驱动视图 view 更新,用户在视图上面进行操作,触发 action,通过 action 来更新数据,视图是无法直接更新数据 state 的。如下图:
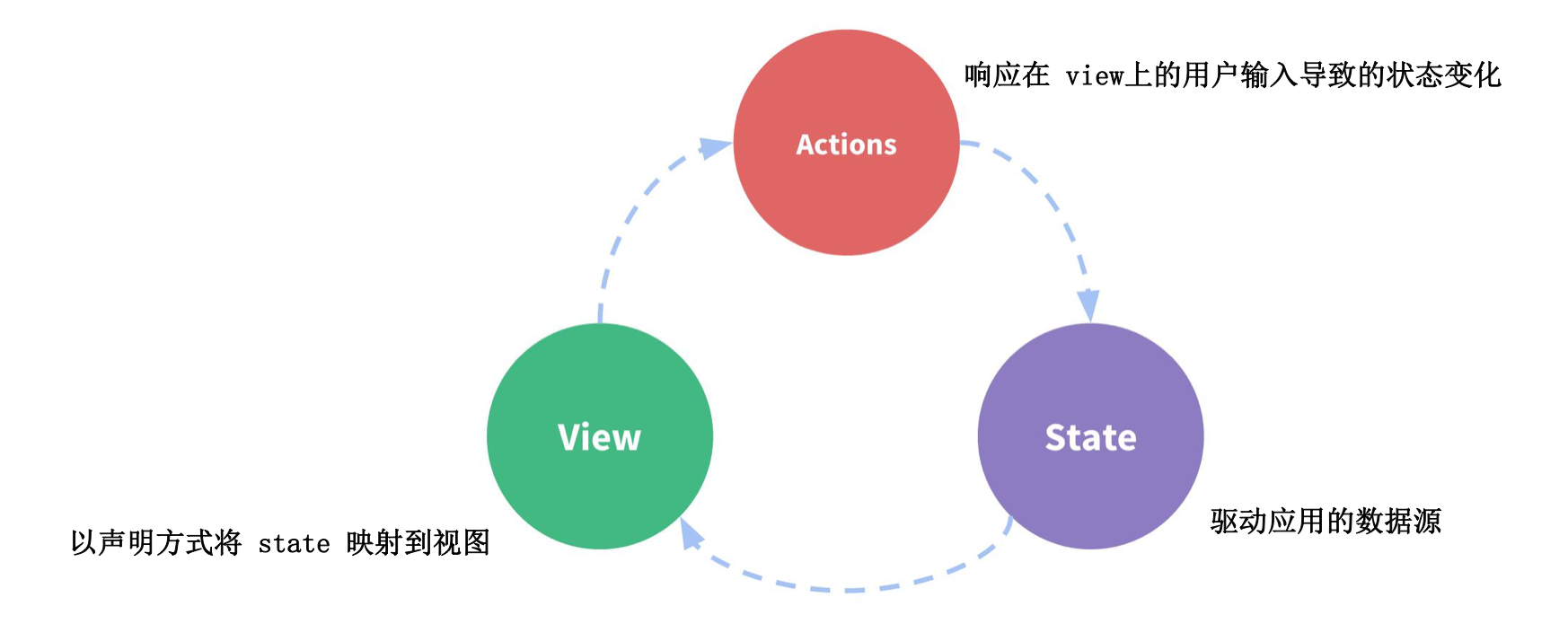
状态管理
正因为 Vue 是单向数据流的,这样就带来了一个问题:多个组件可能会用到同一个数据,如果其中一个组件进行了修改,需要同步到其它组件。
由于使用其它方式,在数据较多的场景下,所花费的成本太过高昂,所以才有了 Vuex。
Vuex 运行机制
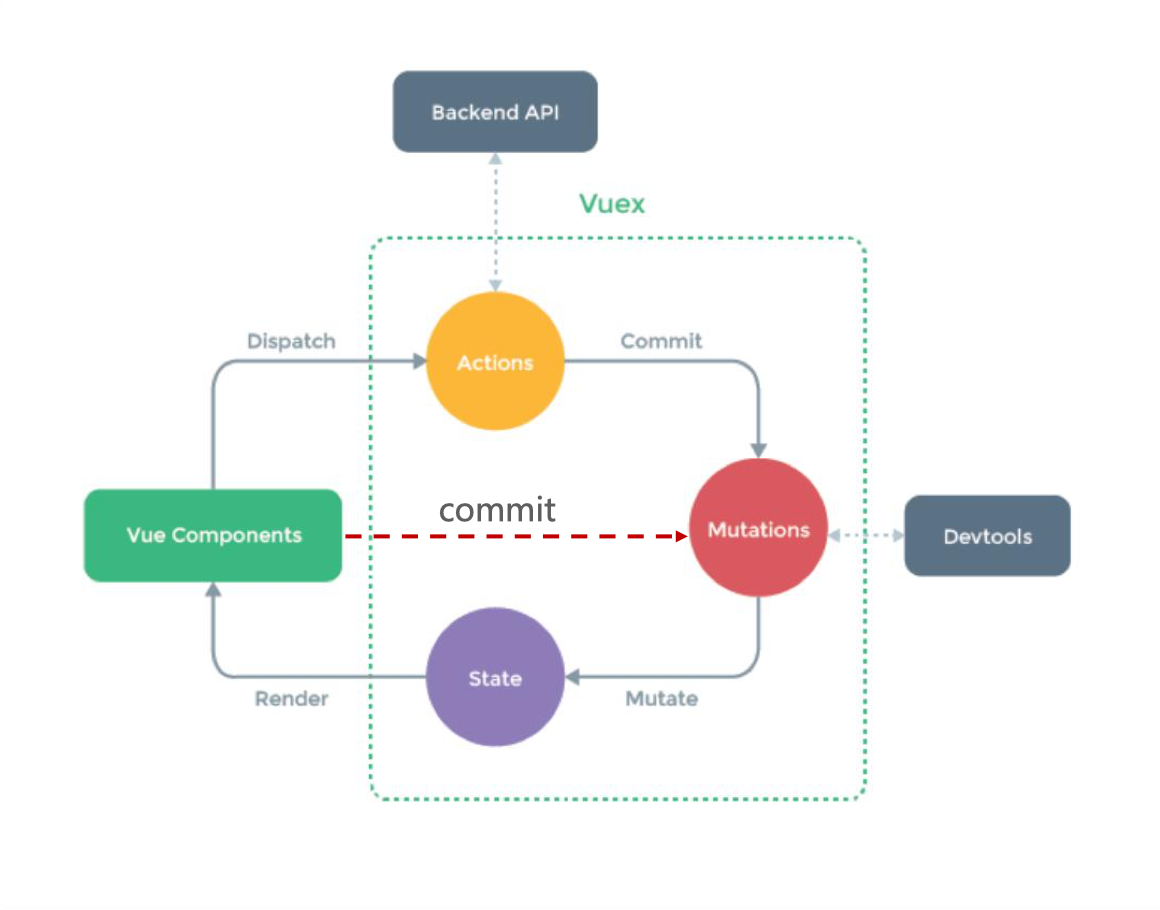
Vuex 提供数据 state 给视图 Vue Component 使用,视图通过 dispatch 派发 action。在 action 中,可以进行进一步的异步操作(比如:ajax),然后通过 commit 的方式提交给 mutation,这样 Devtools 可以记录数据的变化。同时,mutation 最终修改数据 state。
当然,视图也可以直接提交 commit。
Vuex 响应式原理
import Vue from "vue"
const Store = function Store(options = {}) {
const {state = {}, mutations = {}} = options;
this._vm = new Vue({
data: {
$$state: state
}
})
this._mutations = mutations;
}
Store.prototype.commit = function(type, payload) {
if(this._mutations[type]) {
this._mutations[type](this.state, payload)
}
}
Object.defineProperties(Store.prototype, {
state: {
get: function() {
return this._vm._data.$$state
}
}
})
上面代码是关于 Vuex 的微型实现,从中可以看出 Vuex 响应式数据的原理。Vuex 通过 new Vue 的方式,将 state 数据挂载到 data 下面,这样 sate 就间接的变为了响应式数据。
然后,Store 中定义了 commit 方法,内部其实还是调用的 mutation。
在正常使用 state 数据的过程中,我们通常是使用这样的方式进行调用:this.$store.state。为了能够通过这样的方式进行调用,我们需要给 state 定义一个 getter,内部返回的其实是挂载到 data 上的 $$state。
vue-router
Vue Router 是 Vue.js 官方的路由管理器。它和 Vue.js 的核心深度集成,让构建单页面应用变得易如反掌。
vue-router 解决的问题
监听 URL 的变化,并在变化前后执行相应的逻辑;
不同的 URL 对应不同的组件;
提供多种方式改变 URL 的 API(URL 的改变不导致浏览器刷新);
vue-router 底层原理
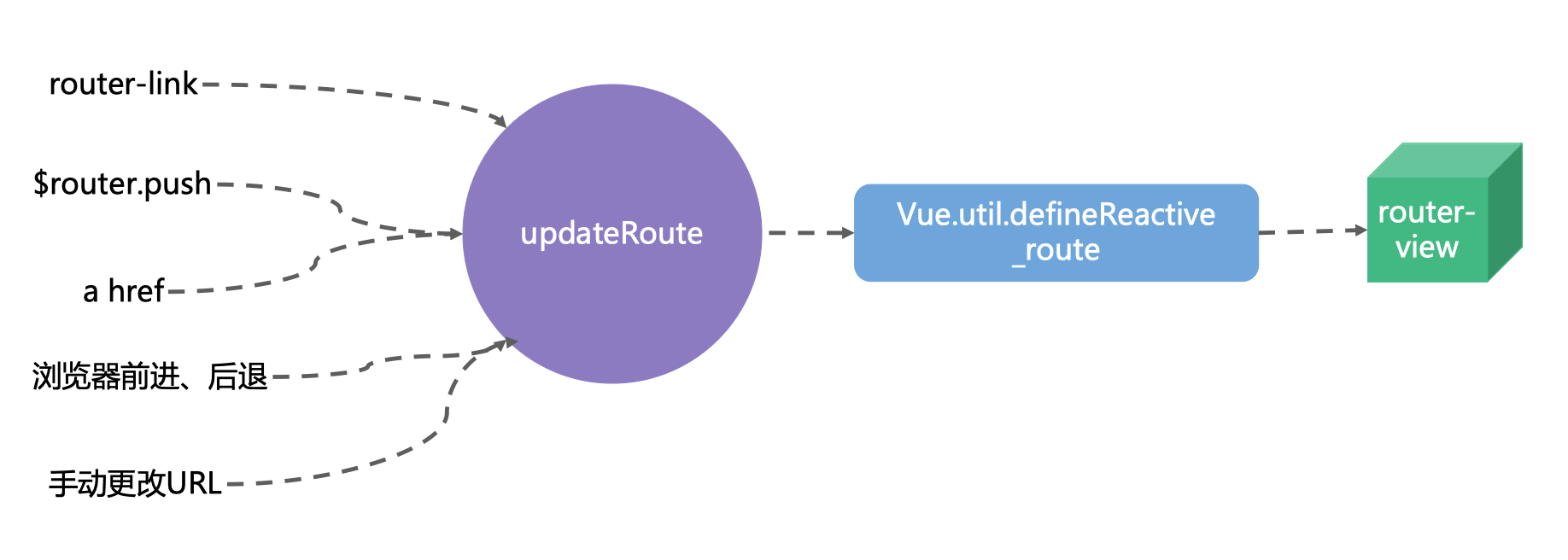
我们定义的路由通过 Vue.util.defineReactive_route 这个 API,变成了响应式的。这时候,通过 router-link、$router.push、a href、浏览器前进和后退或者是手动修改 URL,都会触发 updateRoute 这个操作,通过 updateRoute 修改响应式数据,最终会自动触发 router-view 的更新。
SPA
SPA( single-page application )仅在 Web 页面初始化时加载相应的 HTML、JavaScript 和 CSS。一旦页面加载完成,SPA 不会因为用户的操作而进行页面的重新加载或跳转;取而代之的是利用路由机制实现 HTML 内容的变换,UI 与用户的交互,避免页面的重新加载。
优点:
用户体验好、快,内容的改变不需要重新加载整个页面,避免了不必要的跳转和重复渲染;
基于上面一点,SPA 相对对服务器压力小;
前后端职责分离,架构清晰,前端进行交互逻辑,后端负责数据处理;
缺点:
初次加载耗时多:为实现单页 Web 应用功能及显示效果,需要在加载页面的时候将 JavaScript、CSS 统一加载,部分页面按需加载;
前进后退路由管理:由于单页应用在一个页面中显示所有的内容,所以不能使用浏览器的前进后退功能,所有的页面切换需要自己建立堆栈管理;
SEO 难度较大:由于所有的内容都在一个页面中动态替换显示,所以在 SEO 上其有着天然的弱势。
hash 和 history 路由模式实现原理
hash
早期的前端路由的实现就是基于 location.hash 来实现的。其实现原理:location.hash 的值就是 URL 中 # 后面的内容:
hash 路由模式的实现主要是基于下面几个特性:URL 中 hash 值只是客户端的一种状态,也就是说当向服务器端发出请求时,hash 部分不会被发送;
hash 值的改变,都会在浏览器的访问历史中增加一个记录。因此我们能通过浏览器的回退、前进按钮控制 hash 的切换;
可以通过 a 标签,并设置 href 属性,当用户点击这个标签后,URL 的 hash 值会发生改变;或者使用 JavaScript 来对 loaction.hash 进行赋值,改变 URL 的 hash 值;
我们可以使用 hashchange 事件来监听 hash 值的变化,从而对页面进行跳转(渲染)。
history
HTML5 提供了 History API 来实现 URL 的变化。其中做最主要的 API 有以下两个:history.pushState() 和 history.repalceState()。这两个 API 可以在不进行刷新的情况下,操作浏览器的历史纪录。唯一不同的是,前者是新增一个历史记录,后者是直接替换当前的历史记录
history 路由模式的实现主要基于存在下面几个特性:pushState和repalceState两个 API 来操作实现 URL 的变化 ;我们可以使用
popstate事件来监听 url 的变化,从而对页面进行跳转(渲染);history.pushState()或history.replaceState()不会触发popstate事件,这时我们需要手动触发页面跳转(渲染)。
Nuxt
Nuxt.js 是使用 Webpack 和 Node.js 进行封装的基于 Vue 的 SSR 框架,使用它,你可以不需要自己搭建一套 SSR 程序,而是通过其约定好的文件结构和 API 就可以实现一个首屏渲染的 Web 应用。
SSR
SSR: 服务端渲染(Server Side Render),即:网页是通过服务端渲染生成后输出给客户端。如下图所示:
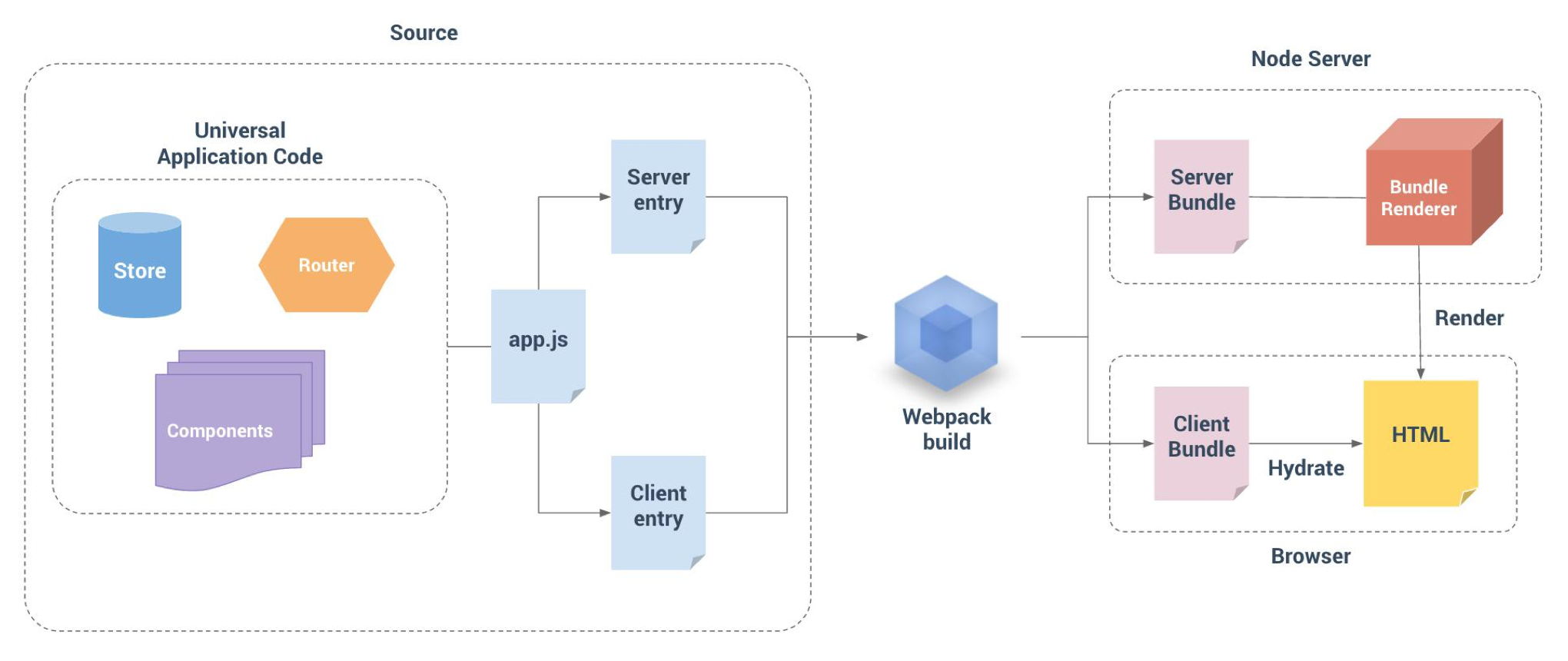
在 SPA 之前的时代,我们的Web架构大都是 SSR,如:Wordpress(PHP)、JSP技术、JavaWeb...或者 DEDECMS、Discuz! 等这些程序都是传统典型的 SSR 架构, 即:服务端取出数据和模板组合生成 html 输出给前端,前端发生请求时,重新向服务端请求 html 资源,路由也由服务端来控制。
预渲染
如果你只是用服务端渲染来改善一个少数的营销页面(如 首页,关于,联系 等等)的 SEO,那你可以用预渲染来实现。
预渲染不像服务器渲染那样即时编译 HTML,它只在构建时为了特定的路由生成特定的几个静态页面,等于我们可以通过 Webpack 插件将一些特定页面组件 build 时就编译为 html 文件,直接以静态资源的形式输出给搜索引擎。
优点
更好的 SEO
因为 SPA 页面的内容是通过 Ajax 获取,而搜索引擎爬取工具并不会等待 Ajax 异步完成后再抓取页面内容,所以在 SPA 中是抓取不到页面通过 Ajax 获取到的内容;而 SSR 是直接由服务端返回已经渲染好的页面(数据已经包含在页面中),所以搜索引擎爬取工具可以抓取渲染好的页面;
首屏加载更快
SPA 会等待所有 Vue 编译后的 js 文件都下载完成后,才开始进行页面的渲染,文件下载等需要一定的时间等,所以首屏渲染需要一定的时间;SSR 直接由服务端渲染好页面直接返回显示,无需等待下载 js 文件及再去渲染等,所以 SSR 有更快的内容到达时间;
缺点
更多的开发条件限制
服务端渲染只支持 beforCreate 和 created 两个钩子函数,这会导致一些外部扩展库需要特殊处理,才能在服务端渲染应用程序中运行;
并且与可以部署在任何静态文件服务器上的完全静态单页面应用程序 SPA 不同,服务端渲染应用程序,需要处于 Node.js server 运行环境;
更多的服务器负载
在 Node.js 中渲染完整的应用程序,显然会比仅仅提供静态文件的 server 更加大量占用CPU 资源 (CPU-intensive - CPU 密集),因此如果你预料在高流量环境 ( high traffic ) 下使用,请准备相应的服务器负载,并明智地采用缓存策略。